
DirBuster is a multi threaded java application designed to brute force directories and files names on web/application servers. Often is the case now of what looks like a web server in a state of default installation is actually not, and has pages and applications hidden within. DirBuster attempts to find these. DirBuster searches for hidden pages and directories on a web server. Sometimes developers will leave a page accessible, but unlinked. DirBuster is meant to find these potential vulnerabilities. This is a Java application developed by OWASP.
For a developer, DirBuster can help you to increase the security of your application by finding content on the web server or within the application that is not required (or shouldn't even be public) or by helping developers understand that by simply not linking to a page does not mean it can not be accessed. In this article you will learn how to execute a brute force scan in a website to find (maybe hidden) directories and files.
1. Start DirBuster
You can start the DirBuster application in 2 different ways:
A. Start with the dirbuster icon
Just search and type DirBuster in the search menu of Kali Linux, in the list of apps there should appear the dirbuster application:
Click on the icon and the app will start.
B. Start with the terminal
Alternatively, you can start DirBuster with the terminal by typing:
dirbusterAnd DirBuster should start:
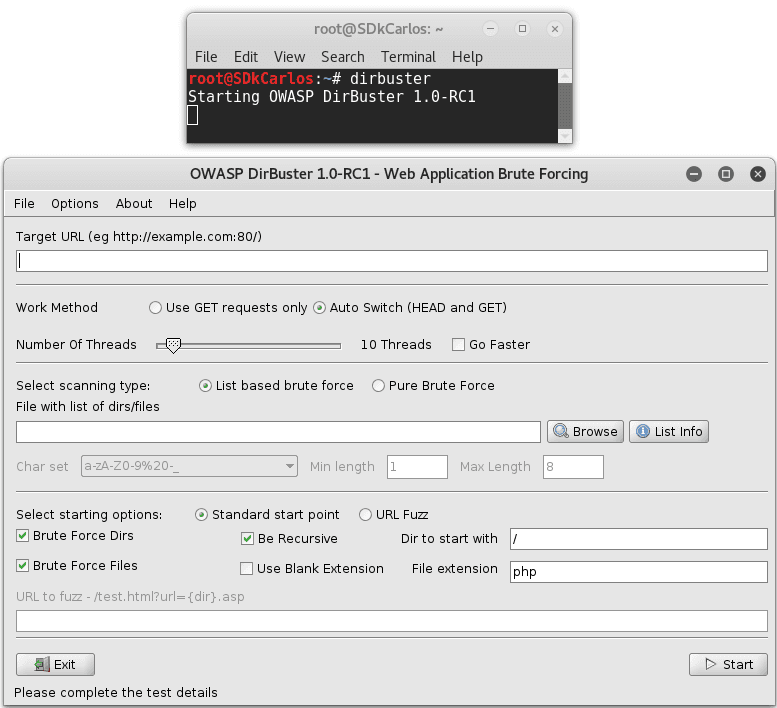
As you can see, with any of the previous methods you should see an user interface that will allow you to list files and directories from a Web url in the port 80.
2. Set target URL and number of Threads
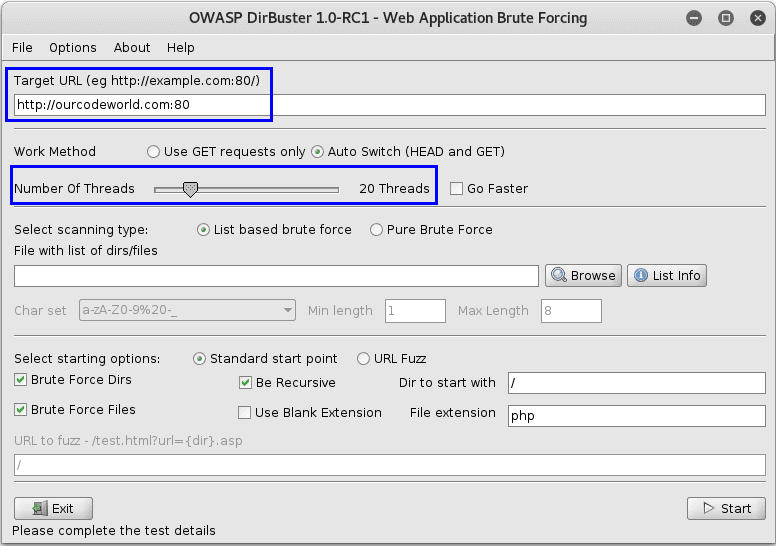
You will need obviously to provide the URL or IP address of the website from which you want more information, this URL needs to specify the port in which you want to specify the scan. The port 80 is the primary port used by the world wide web (www) system. Web servers open this port then listen for incoming connections from web browsers. Similarly, when a web browser is given a remote address (like ourcodeworld.com or docs.ourcodeworld.com), it assumes that a remote web server will be listening for connections on port 80 at that location. To specify the port 80 in the URL, you just need to add "double point and the number of the port at the end of the URL" e.g http://ourcodeworld.com:80.
The number of threads that will be used to execute the brute forcing depends totally on the hardware of your computer. In this example we are going to use only 20 threads as our computer ain't so powerful and we want to do other things during the scan of DirBuster:
3. Select list of possible directories and files
As mentioned previously, DirBuster needs a list of words to start a brute force scan. But don't worry, you don't need to make your own list or necessarily search for a list in Internet as DirBuster has already a couple of important and useful lists that can be used for your attack. Just click on the Browser button and selected the wordlist file (they're normally located at /usr/share/dirbuster/wordlists) that you want to use for the brute force scan:

In this case we are going to use the directory-list-2.3-medium.txt file.
Note
If the included dictionaries of DirBuster aren't enough for you, then you can search for more in Google (in this repo you will find some useful lists too).
4. Start brute force scan
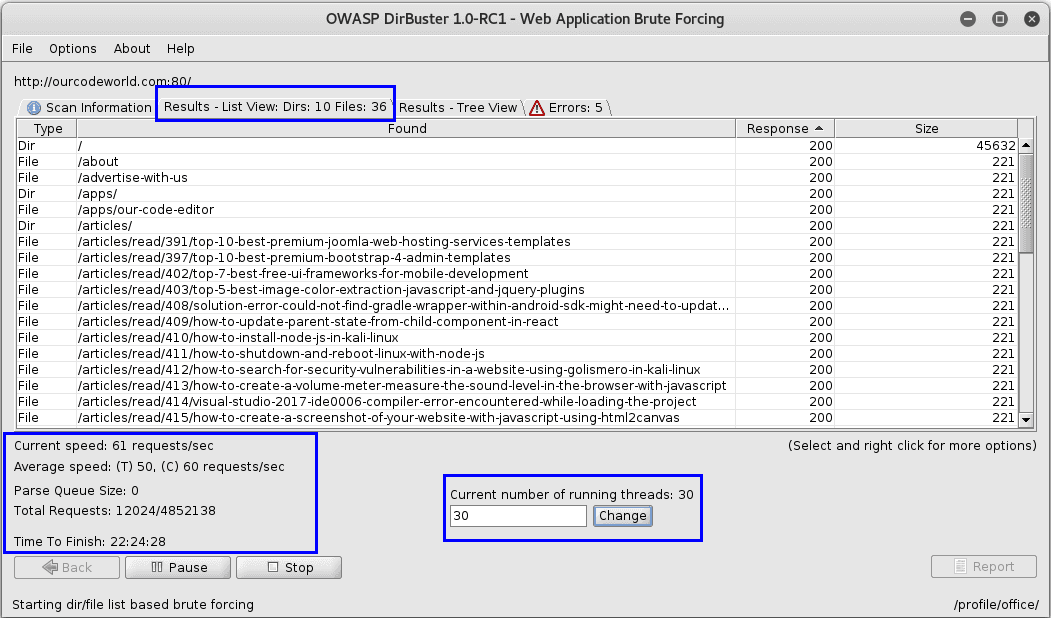
To start the scan on the website, just press the Start button in the GUI. In this step DirBuster will attempt to find hidden pages/directories and directories within the providen url, thus giving a another attack vector (For example. Finding an unlinked to administration page).
Note
You can change the number of threads to use during the scan, in this way you can accelerate the process according to the performance shown by your computer. In this case there were initially 20 threads, but we modify it to use now 30.
5. Generate the report (optional)
Once the scan finishes (or you stop it) the Report button (disabled while the scan runs) will be enabled. With the report window you can export the scanned urls of the found directories and files into different formats as plain text, xml or csv. Just fill the form and then click on Generate report:

You can use this list for example to write some kind of scraper with Python or another language of your preference and then download all the available webpages of the scanned website (as long as the status code was 200).
Happy information gathering !






