
Recently, working on a special project that involved the usage of a third party database that was in CSV (comma separated values) format, I quickly noticed my lack of knowledge to manipulate sets of information of considerable size using my favorite languages. Due to the lack of time as well, i couldn't afford rewriting some generic code that i already have to import that kind of data into my database with PHP.
1. Download CSVSplitter
CSVSplitter is a desktop application made for windows by the ERD Concepts company. This tool allows you to split large comma separated files (CSV) into smaller files based on a number of lines (rows). CSV Splitter will process millions of records in just a few minutes. It will work in the background so you can continue your work without the need to wait for it to finish, however as a personal tip, if your dataset is huge (compared to the 25GB of our example), we recommend you to let only the mentioned application opened, so it will use all the available resources of your computer and the processing time will be faster and won't mess up with the performance of other applications that you may have opened at the same time.
You can directly download the tool from this link or alternatively see the list of all the tools offered by the ERD company and download it from the list here. The zip from the website will contain a simple portable .exe file and a .txt file, necessary to work along with the executable, just extract the content in some directory and you're ready to work:
For more information about this tool, don't forget to visit the ERD Concepts official website here.
2. Splitting CSV datasets
To get started, you will need to have the CSV file that you want to split into smaller chunks. In our example, we have some file whose uncompressed filesize is of 25GB, obviously, opening such a file in Excel or even a plain text editor will cause the program to crash! Take for example the following CSV structure that includes the headers (first line specifying the columns):
id, name, description
1, "Bruce Wayne", "I'm Batman"
2, "Alfred Pennyworth", "I'm Batman's Butler"
...
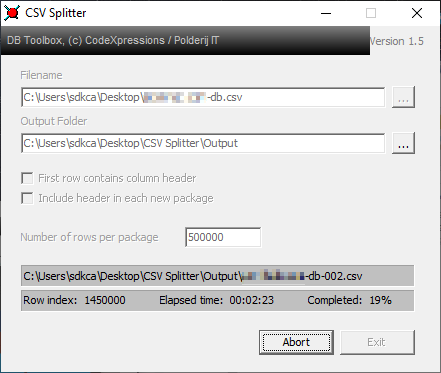
7691502,"Comissioner Gordon", "Best Comissioner Ever"As we describe, the file has 7.514.701 rows, so we could ideally split the file into chunks of 250.000 rows every file, so we may obtain a decent performance in our own scripts.
You only need to open the application and select the input CSV file that you want to process and as well the output directory where the results should be stored. There are 2 checkboxes that allow you to:
- First row contains column header: if your CSV structure describes the first row as the name of the columns of every field, you should mark this so the first row won't be handled as data.
- Include header in each new package: this option specifies if the first row did have the column header, then every output file should contain the header as well.
In the Number of rows per package, you may specify a decent amount of rows that you scripts could handle, for example in our case, chunks of 250K would be ideal. Finally click on start so the application will start splitting the data into smaller chunks. With our dataset example of 7.514.701 rows (filesize of ~25GB), the results were:
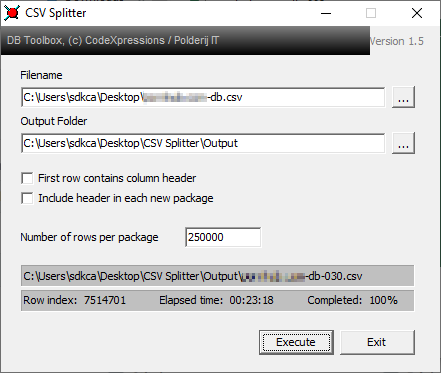
It took 23 minutes to process the entire file and generated 30 chunks (files) from the original one. The output files look like:

Happy coding ❤️!

