
DOM Document is a PHP class that represents an entire HTML or XML document and serves as the root of the document tree. It's used to easily create or load HTML or XML and modify it to your will, search elements, and so on. In the last days, I needed to retrieve the source (URL) of the images loaded inside an HTML document and decided to this easily with the mentioned class and DomXPath easily in PHP. Unfortunately, while loading very basic and standard HTML 5, I discovered the following issue that curiously, although this triggers an exception, the message explicitly talks about a warning:
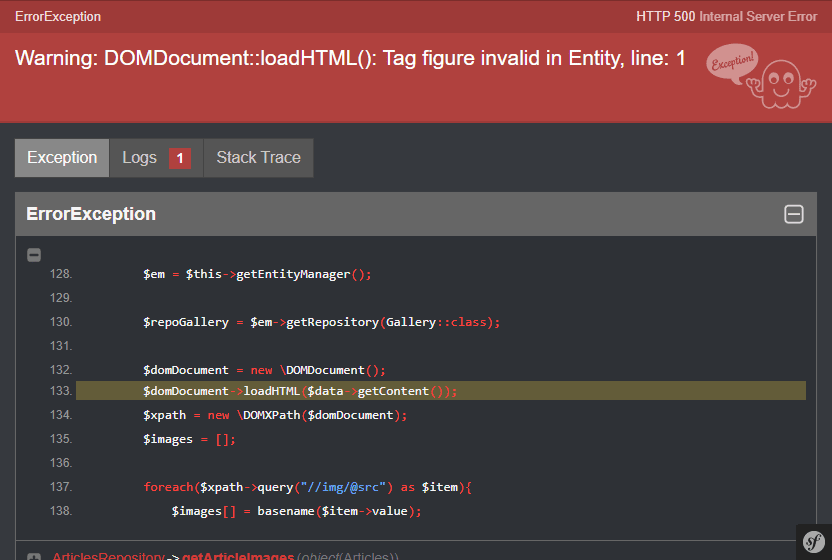
Warning: DOMDocument::loadHTML(): Tag XXXXXX invalid in Entity
Why does this exception appear
The execution of the following PHP code will trigger the mentioned "Warning" that screws up your code:
<?php
// An example HTML document:
$html = <<<'HTML'
<!DOCTYPE html>
<html>
<head>
<title>Testing</title>
</head>
<body id='foo'>
<h1>Hello World</h1>
<figure class="image">
<img src="https://ourcodeworld.com/public-media/articles/cookielessdomain-5fa35742d669f.png" />
<figcaption>Caption</figcaption>
</figure>
</body>
</html>
HTML;
$domDocument = new \DOMDocument();
$domDocument->loadHTML($html);
$xpath = new \DOMXPath($domDocument);
foreach($xpath->query("//img/@src") as $item){
echo "<br> Image: ". basename($item->value);
}Then, on the browser the following errors will appear:
Warning: DOMDocument::loadHTML(): Tag figure invalid in Entity, line: 7 in \demo.php on line 27
Warning: DOMDocument::loadHTML(): Tag figcaption invalid in Entity, line: 9 in \demo.php on line 27
Image: cookielessdomain-5fa35742d669f.pngI discovered this error when trying to search for the image URLs inside an HTML structure to obtain the src attribute value of each of them. The failure is by itself on the DOMDocument class. In our HTML, we do have 2 HTML5 entities (<figure> and <figcaption>) that aren't recognized by the old DOMDocument parser of PHP.
Solution
There are 2 possibles solutions for this problem:
A. Ignoring warnings
The first thing you can try is to simply ignore these warnings suppressing them, forcing libxml to handle the errors internally with libxml_use_internal_errors (you can retrieve them with some code), and then cleaning them as specified in the following example:
// 1. Create document
$domDocument = new \DOMDocument();
// 2. Handle errors internally
libxml_use_internal_errors(true);
// 3. Load your HTML 5
$domDocument->loadHTML($html);
// 4. Do what you need to do without the warning ...
// 5. Clear errors
libxml_clear_errors();As the error itself is caused by the underlying libxml library, in theory, your entire code (or at least a big part of it) will work anyway if we ignore the mentioned exception. If your code still works as expected, then you don't need to try the second possible solution. If you need to know about the errors or warnings, you can obtain them and do what you need with them as well:
// 1. Create document
$domDocument = new \DOMDocument();
// 2. Handle errors internally
libxml_use_internal_errors(true);
// 3. Load your HTML 5
$domDocument->loadHTML($html);
// 4. Do what you need to do without the warning ...
$xpath = new \DOMXPath($domDocument);
foreach($xpath->query("//img/@src") as $item){
echo "<br> Image: ". basename($item->value);
}
// 5. Clear errors
$errors = libxml_get_errors();
// 6. If you need to know about the errors or warnings
foreach ($errors as $error)
{
/* @var $error LibXMLError */
/*
each $error variable contains a LibXMLError object with the following properties
array(
'level' => 2,
'code' => 801,
'column' => 28,
'message' => 'Tag figcaption invalid',
'file' => '',
'line' => 10,
)
*/
}However, if for some reason, after ignoring the warnings, your code is not behaving as expected, then you may try our second possible solution for this problem.
B. Use another parser (DomCrawler)
At the end of this problem, you need to achieve something with the DOM, probably searching inside of it and not modifying it, so there's a good chance that your problem will be solved if you rely on an HTML5 capable DOM Parser and that's when the DomCrawler library of Symfony shows up. The DomCrawler component eases DOM navigation for HTML and XML documents.
To work with this library, proceed with the installation using Composer:
composer require symfony/dom-crawlerFor more information about this library, please visit the official Github repository here or the official website here.
After the installation, you should be able to include the library in your code. The following snippet shows basically the same thing we did on the original code with DOMXPath that was searching for the images on the provided HTML 5:
<?php
require 'vendor/autoload.php';
use Symfony\Component\DomCrawler\Crawler;
// An example HTML document:
$html = <<<'HTML'
<!DOCTYPE html>
<html>
<head>
<title>Testing</title>
</head>
<body id='foo'>
<h1>Hello World</h1>
<figure class="image">
<img src="https://ourcodeworld.com/public-media/articles/cookielessdomain-5fa35742d669f.png" />
<figcaption>Caption</figcaption>
</figure>
</body>
</html>
HTML;
// 1. Create an instance of the crawler with our HTML
$crawler = new Crawler($html);
// 2. Search for the images and src attribute using the XPath filter and store them into an array
$images = $crawler->filterXPath('//img/@src')->each(function (Crawler $node, $i) {
return $node;
});
// 3. Iterate over the found images and obtain what we want
foreach($images as $image){
echo "Image: "$image->text();
}Which should output in the browser:
Image: https://ourcodeworld.com/public-media/articles/cookielessdomain-5fa35742d669f.pngAs you can see, our requirement was solved and there were no warnings of unknown entities while loading the HTML in the crawler.
Happy coding ❤️!

