
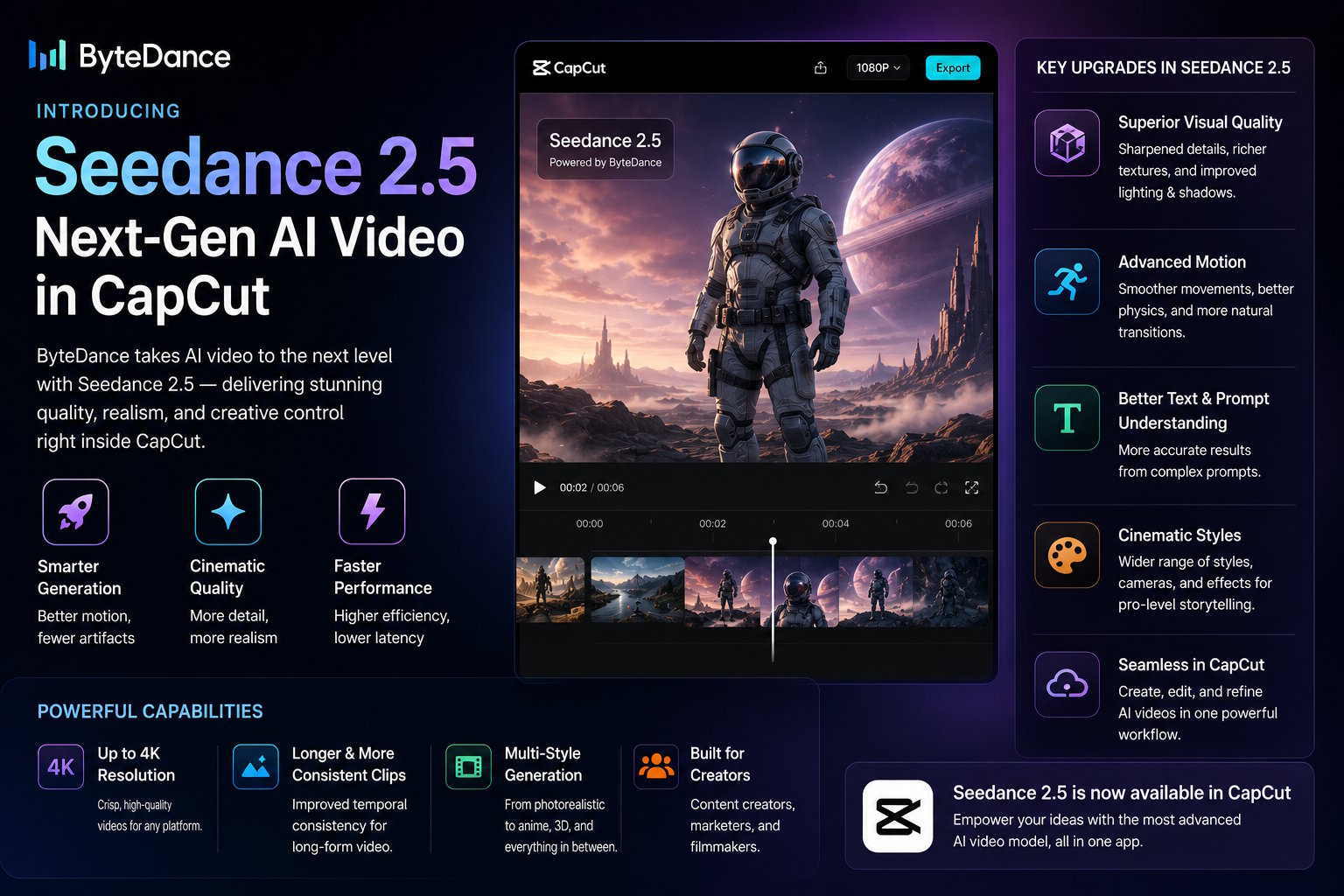
Digital video creation is undergoing its most significant paradigm shift yet. ByteDance, the global technology powerhouse behind TikTok and an industry leader in multimodal artificial intelligence research, has officially launched its highly anticipated next-generation video foundation model, integrated natively into its flagship editing ecosystem. Available immediately for creators worldwide, users can now experience the powerful, multimodal cinematic capabilities of Seedance 2.5 Online directly within CapCut's web-based production suite.
This new rollout marks a decisive leap forward from research laboratory demonstrations to mainstream, commercial-grade creative production. While previous artificial intelligence video iterations were frequently bottlenecked by restrictive output limits, floating frame anomalies, and rapid identity drift, the updated version changes the equation entirely. Creators, digital marketers, and independent filmmakers can now generate continuous, highly consistent 30-second native 4K visual sequences via a single structural prompt.
Rewriting the Limits of AI Video Generation
The deployment of this new architecture addresses the exact technical pain points that have frustrated professional production teams utilizing AI workflows. Most legacy models generate video in fleeting 3- to 5-second increments, requiring tedious manual stitching and extensive post-production editing to assemble a cohesive scene.
By scaling native rendering to a full 30 seconds, the model gives complex actions, detailed product demonstrations, and narrative sequences the room they need to breathe. The system establishes an intuitive timeline that naturally manages pacing, camera physics, and emotional transitions without losing structural integrity halfway through the render.
Beyond simple clip elongation, the core differentiator powering the engine is its massive, multi-input reference control.
- Multimodal Input Array: The updated system accepts up to 50 distinct visual, audio, or spatial reference points simultaneously—a dramatic scale-up from the 12-reference limit of prior versions.
- Absolute Visual Fidelity: Creators can supply full multi-angle character turnarounds, exact product geometry sheets, environment lighting references, and brand color swatches directly into the engine's initialization panel.
- Multi-Video Motion Control: Users can inject separate reference videos to act as explicit frameworks—one clip to dictate tracking camera moves, a second to govern physical action rhythm, and a third to map stylized environmental lighting changes.
The result is a controlled, predictable system that behaves less like an unpredictable algorithmic text-to-video generator and more like a precise, digital pre-visualization director.
Bridging the Gap: Casual Content to High-Fidelity Commercials
The integration of this model into the CapCut ecosystem democratizes professional-tier filmmaking tools for independent operators and enterprise marketing departments alike. By lowering financial and temporal entry barriers, teams can bypass the staggering capital requirements of traditional commercial videography—including studio rentals, complex equipment setups, and prolonged post-production cycles—slashing standard concept-to-delivery timelines from weeks to minutes.
For modern digital environments, the operational advantages manifest across several specific commercial vectors:
1. Consistent Brand Marketing & E-Commerce
Preserving absolute product consistency across varied ad sets has historically been the primary limitation of generative marketing. With multi-angle image constraints, a physical product can be rendered perfectly inside diverse, highly contextualized lifestyle settings. Because a 30-second runtime perfectly matches standard programmatic social advertisement lengths, marketing teams can spin up hyper-localized ad variations and conduct seamless visual A/B testing at scale without incurring extra production expenses.
2. Narrative Filmmaking and Digital Pre-Visualization
Independent storytellers are utilizing the extended 30-second generation capacity to establish complex cinematic sequences. By feeding detailed scene prompts alongside explicit camera tracking videos, directors can effortlessly plan continuity, block out intricate character movements, and build realistic physics-defying action sequences, approaching the detailed workflows utilized by elite Hollywood pre-visualization departments.
3. Optimized Vertical Short-Form Flywheels
The engine's native structural algorithms are fine-tuned for vertical 9:16 environments, making it an automated powerhouse for platforms like TikTok, Instagram Reels, and YouTube Shorts. Content creators can take a single core visual concept, input localized script modifications, and generate distinct multi-shot sequences that maintain identical character faces, clothing textures, and thematic aesthetics throughout the entire narrative arc.
Streamlined Browser-Based Production
The inclusion of the technology as a web tool eliminates the need for expensive local hardware arrays or high-end graphics processing units. The cloud-rendered interface transforms standard web browsers into comprehensive studio bays.
The standard user journey is designed around an iterative, low-friction pipeline. Creators outline their narrative scene within a textual input field, detailing precise subject details, lighting conditions, and camera directions. Next, they anchor the generation by uploading relevant character identity sheets or product imagery. After designating targeted technical parameters—including specific aspect ratios and resolution targets—the cloud engine processes the assets, outputting a high-fidelity, publishable video file ready for direct timeline editing, caption placement, and immediate platform distribution.
Vertical Integration and the Future Distribution Network
By embedding its premier video generation asset directly into CapCut’s existing user base of hundreds of millions of monthly active users, ByteDance is effectively consolidating the entire lifecycle of modern internet media. The traditional workflow silo—where creators had to jump between isolated AI generation sites, independent desktop video editors, and localized social media publishing apps—has been collapsed into a singular, unified loop. Media is generated, refined with precise editorial controls, and distributed to global audiences from a single browser tab.
As the underlying models continue to scale their multi-modal capabilities, the boundaries separating initial ideation from professional media output will keep dissolving. The launch of this updated platform isn't simply an incremental upgrade to a digital toolset; it stands as a fundamental reconfiguration of how human intent, brand identity, and machine intelligence collaborate to shape the future of global visual media.
About ByteDance
Founded in 2012, ByteDance is a global technology company operating a range of content platforms that inform, educate, entertain, and inspire people across languages, cultures, and geographies. Dedicated to building innovative platforms that enable global creation and communication, ByteDance continues to pioneer advancements in large-scale machine learning, multimodal artificial intelligence, and digital content ecosystems.
Media Contact
For media inquiries, interviews, or additional technical information regarding the latest release, please contact the corporate press office:
- Contact Person: Ming Hu
- Email: [email protected]
- Company Name: ByteDance

