

What if every client who called your company received a prompt and precise response without having to wait on hold?
That is no longer a fantasy. Phones had been used for years, but they were inadequate, with long lines, useless menu options, and irate consumers hanging up. The majority of companies were aware of it but took no action.
That era is over.
AI voice agents now handle real queries in real time by taking the pressure off support teams and stopping brands from losing customers over something completely avoidable.
The technology works. What separates a voice agent that builds trust from one that damages it has nothing to do with budget. It comes down to how well the system is built, tested, and looked after once it goes live.
What’s Under the Hood?
A voice agent is a chain of technologies passing work to each other. One piece captures speech and turns it into text. Another reads that text and works out what the person wants. A backend pulls the relevant data. The system then generates a spoken response.
Everything operates as it should. The entire loop takes less than two seconds, and if anything lags or misinterprets, the caller is informed immediately.
Before going into a complete pipeline design, this article on how to convert voice to text with JavaScript using the webkitSpeechRecognition API is a good starting point for anyone who is unfamiliar with the idea of real-time speech-to-text conversion.
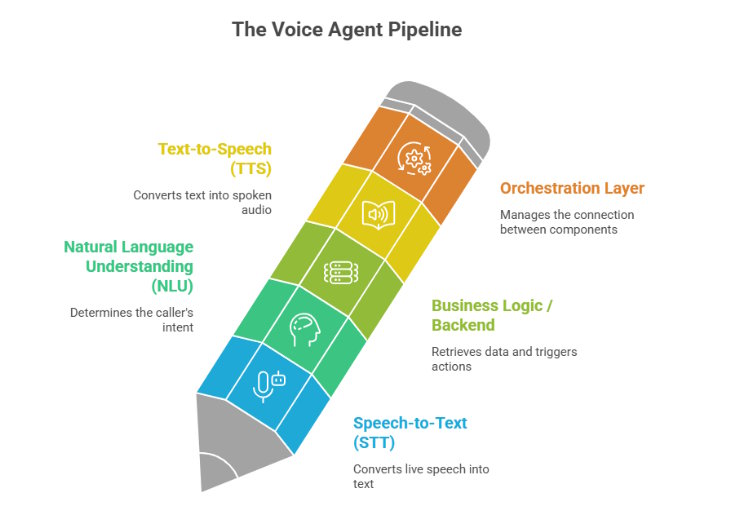
Here is what that chain looks like:
|
Component |
Role |
Example Tools |
|
Speech-to-Text (STT) |
Converts live speech into text |
Deepgram, Whisper, Google STT |
|
Natural Language Understanding (NLU) |
Figures out what a caller wants |
Rasa, Dialogflow, Claude |
|
Business Logic / Backend |
Pulls data or triggers the right action |
REST APIs, Databases, CRMs |
|
Text-to-Speech (TTS) |
Turns a response into spoken audio |
ElevenLabs, Amazon Polly, Azure TTS |
|
Orchestration Layer |
Manages how everything connects |
Custom middleware, LangChain |
When a voice agent sounds robotic or lags, people blame the AI. Most of the time, the problem sits somewhere in this chain. A backend that takes too long. A TTS engine paired with a sharp NLU that makes the whole thing sound mismatched. A transcription layer that falls apart when someone speaks with an accent. One weak link defines the whole experience, and many callers have no patience for it.
Platform or Custom Build?
This is the first real decision, and everything downstream flows from it.
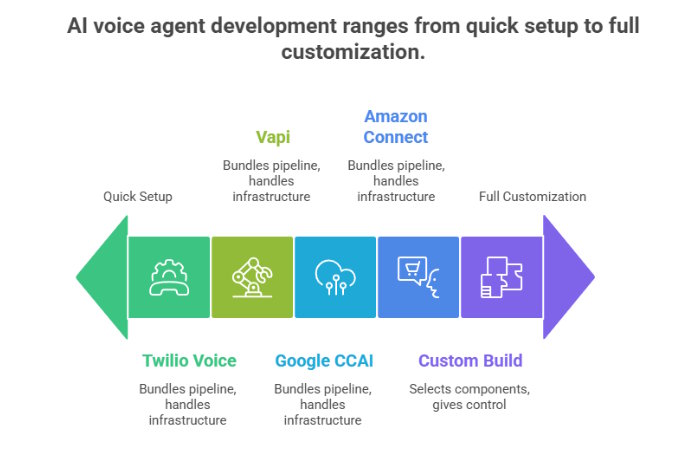
Platform route
Twilio Voice, Vapi, Google CCAI, and Amazon Connect bundle most of the pipeline and handle infrastructure. Teams without dedicated AI engineers, or businesses handling fairly standard queries like appointment booking or order status, can get something functional live without months of custom work.
For businesses still deciding where AI fits into their support stack, this overview of using AI for better customer support lays out the integration options clearly.
Limits show up eventually. When brand voice matters, when the domain is specific, and when queries get complex, platform constraints turn into real blockers, and workarounds get messy fast. The out-of-the-box voice also tends to sound identical to dozens of other companies using the same provider, which is not great for brand identity.
Custom route
Picking each component separately takes longer but gives real control. The right STT provider for your audience, a language model suited to your domain, and a TTS engine that sounds the way your brand should sound.
Not all voice platforms are built equally. Some handle TTS well but fall apart on conversational turns. Others offer voice APIs but lack a production-ready agent layer.
Before committing to either direction, it helps to understand the capabilities of a modern AI voice agent platform.
For instance, Murf operates across text-to-speech, conversational AI, voice agents and voice APIs in one platform. That means fewer integration points and a more consistent voice output.
The gap between platform limitations and custom builds often comes down to this: How well does the underlying voice technology perform under real conditions? A platform that covers all three layers answers that question before it becomes a problem.
Building It Out
- Narrow down the scope first
Every team overestimates what the first version needs to do. Voice agents that work well started small: three to five query types that come up constantly and eat the most support time. Get those right. Expand once the foundation holds up under real traffic and the team understands where the edge cases live.
- Test the speech layer with poor audio
Clean recordings are a useless benchmark. The STT engine will face background noise, spotty mobile connections, heavy accents, people talking fast, people trailing off mid-sentence, and callers who change their minds halfway through a sentence. Testing needs to reflect real conditions; production becomes the first real test, and that never ends well.
Streaming STT beats batch processing for live calls. Processing begins while a caller is still talking, which cuts latency in a way that registers on the other end of the line.
Self-generated
- Build the NLU layer for how people talk
Callers do not speak in neat complete sentences. A solid NLU setup needs to handle:
- Direct requests with clear intent
- Vague or half-finished inputs needing a follow-up question
- Context carried over from earlier in the same call
- Off-topic inputs that need redirecting without breaking the flow
For anyone building this from scratch on the web, getting started with the Speech Recognition API in JavaScript covers the fundamentals of language support, real-time transcription, and how to wire the API into a working application.
- Write for someone listening, not reading
Long sentences fall apart when spoken aloud. Formal phrasing sounds strange coming from a voice agent. Response templates need to sound the way a knowledgeable person would explain something on a phone call: short, direct, nothing pulled from a policy document or a knowledge base article written for a screen.
Run every template through the TTS engine and listen before it reaches a real caller. Things that read fine often sound completely unnatural when spoken, and catching that before launch costs nothing compared to catching it after.
- Stage it properly
Real traffic always surfaces things simulated traffic misses, but simulated traffic still catches plenty. Listen to staging recordings carefully. Look for where conversations fall apart, not just technical errors, but moments where callers get confused, repeat themselves, or go quiet because the agent said something that made no sense.
After launch, the containment rate, intent accuracy, handle time, and satisfaction scores are worth watching closely. Listening to real calls regularly tells the part of the story that numbers miss entirely.
What May Go Wrong After Launch
|
Challenge |
Why It Matters |
How to Address It |
|
Latency spikes |
Anything past two seconds breaks conversational flow |
Tighten each pipeline stage; look at edge deployment |
|
Accent and noise problems |
Real-world accuracy drops without proper training data |
Train on diverse audio; layer in noise suppression |
|
Context dropping mid-call |
Treating each turn as a fresh conversation frustrates callers |
Build session memory using vector stores |
|
Escalation handled badly |
Agents that keep pushing when they should hand off can harm the experience |
Set clear handoff triggers; pass full context to a human agent |
|
Security gaps |
Voice data is sensitive and often regulated |
Encrypt streams end-to-end; stay compliant with GDPR and HIPAA |
The escalation point matters more than most teams expect. A clean handoff with the full conversation passed along to a human picking it up feels seamless to a caller. A dropped handoff where everything has to be explained again from scratch is worse than not having a voice agent at all. Callers who experience that once rarely trust the system again.
After Launch Is Where Teams Usually Drop the Ball
Teams tend to focus heavily on the build phase. Maintenance gets treated as an afterthought, and that is where performance erodes over time.
Deloitte estimates AI voice tools can cut support costs by 30 to 40 percent, but that figure assumes the system is being actively maintained and improved after launch, not left to run on its own.
- Real patterns show up in conversations, not in aggregate numbers sitting in a reporting tool
- NLU retraining needs a regular schedule. Language shifts and a model trained on last year's data drift further from how callers talk with every passing month
- Response phrasing should be tested and iterated on continuously. Small wording changes move containment rates more than most teams expect, and the only way to find a better version is to test
- Peak load performance is a separate test from average load. A system handling normal traffic cleanly can fall apart when call volume spikes during a product issue, a promotion, or an unexpected outage
What It All Comes Down To
The companies with the biggest budgets are not the ones that benefit the most from voice agents. They are the ones who began small, had a close relationship with real data, and continued to maintain the system after it was launched.
There’s a common pattern among projects that get quietly shelved: no one keeps working on them after launch.
Are you prepared to explore this topic further? For real-world code examples, tutorials, and helpful instructions that transform theory into something that can be implemented, check out ourcodeworld.com.

